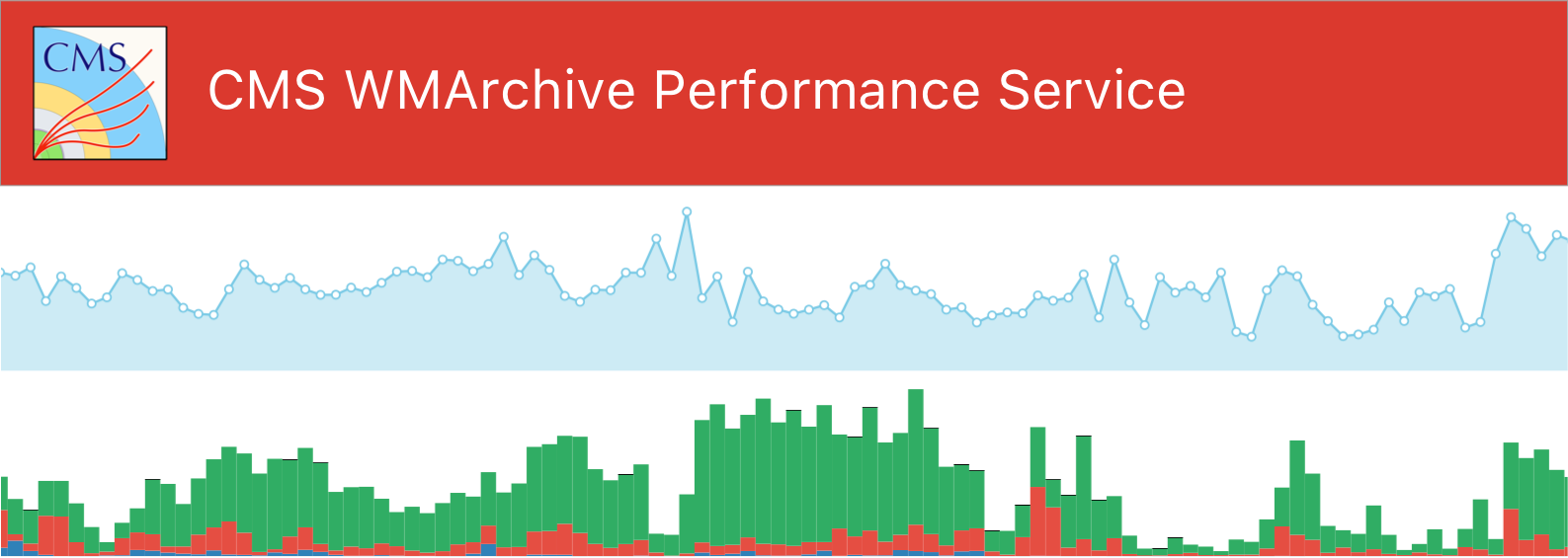
CERN Summer Student Programme
A data visualization platform I created in 2016 for the CMS experiment with Python, Apache Hadoop, Apache Spark, MongoDB and D3.js.
This project is part of the WMArchive project that provides long-term storage for the CMS workflow and data management framework job reports (FWJRs). An aggregation pipeline regularly processes the distributed database of FWJRs to collect performance metrics. An interactive web interface visualizes the aggregated data and provides flexible filters and options to assist the CMS data operators in assessing the performance of the CMS computing jobs.
From README.md in the nilsvu/WMArchiveAggregation GitHub repository:
WMArchive Performance Service
CERN Summer Student Programme 2016
- Author: Nils Leif Fischer
- Supervisors:
- Valentin Kuznetsov, Cornell University
- Dr. Dirk Düllmann, CERN
- Date: June 27, 2016 to September 23, 2016
-
Abstract:
This project is part of the WMArchive project that provides long-term storage for the CMS workflow and data management framework job reports (FWJRs).
An aggregation pipeline regularly processes the distributed database of FWJRs to collect performance metrics. An interactive web interface visualizes the aggregated data and provides flexible filters and options to assist the CMS data operators in assessing the performance of the CMS computing jobs.
- Original proposal
- Report in the CERN CDS
Overview
The CMS production agents schedule jobs on the computing grid. When a job finishes it generates a FWJR. The agent then posts this FWJR to the WMArchive REST server that buffers it in a short-term MongoDB database. Then every day the new job reports are converted into a binary Avro file format and migrated to the long-term HDFS storage. This long-term storage is designed to hold millions of these FWJR documents for an indefinite amount of time. This architecture is summarized in the diagram below:
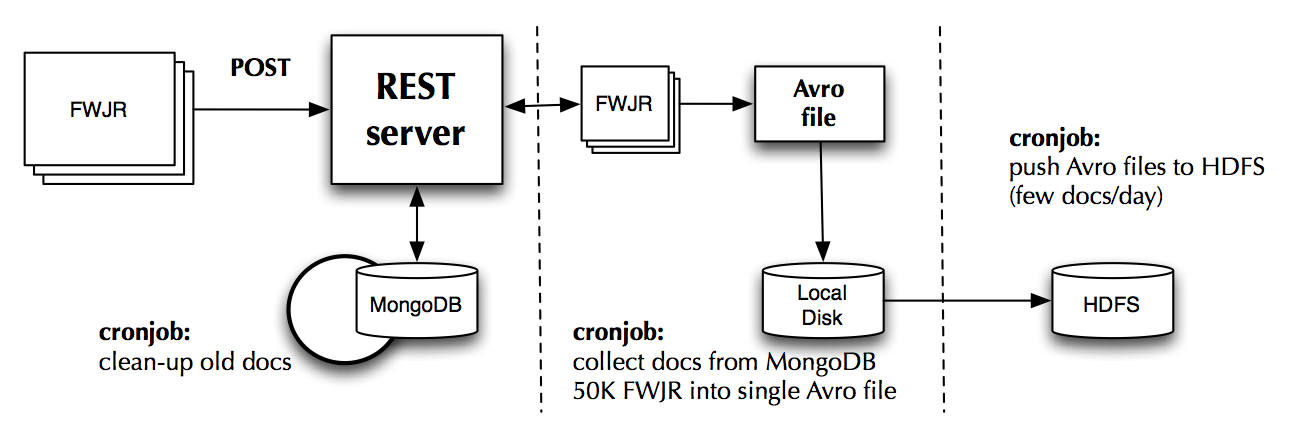
The WMArchive Performance Service project is about retrieving this data stored in the long-term archive and visualizing it in a web interface for CMS data operators to investigate.
Of course to access the data in the long-term HDFS storage it is necessary to schedule jobs that retrieve the data, and those can take a significant amount of time. So to provide a responsive user interface I constructed an aggregation pipeline that regularly processes the distributed database of FWJRs to collect performance metrics and cache the aggregated data back in the MongoDB, where it is quickly accessible by the REST server and the UI. So this cache is not data on each individual job report but instead aggregated data grouped only by a number of attributes data operators may want to filter by, so for example the job success state, its host or its processing site.
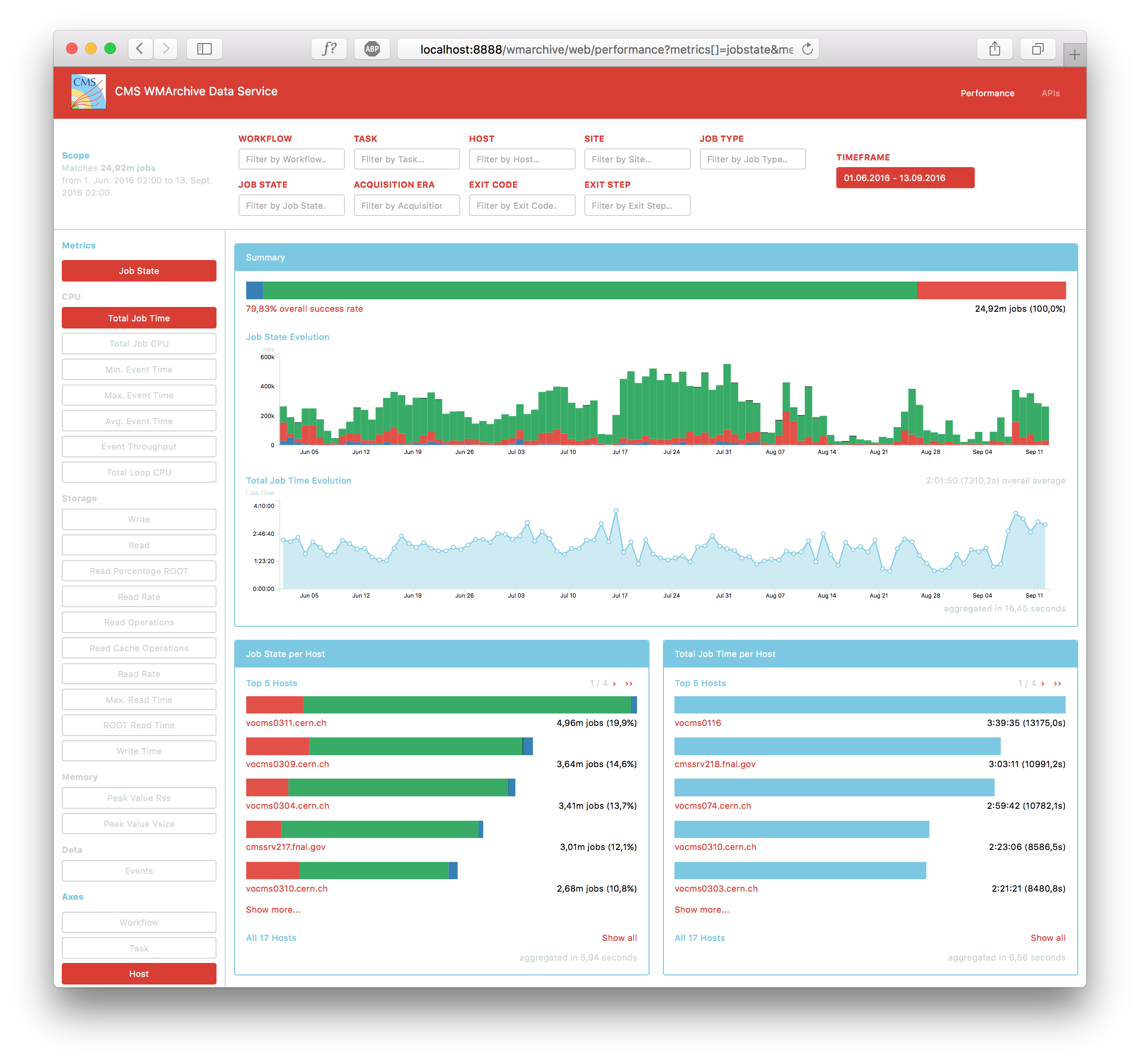
The second part of the project is to build a web interface for CMS data operators to visualize and investigate the aggregated data. It provides flexible filters and options to assist the CMS data operators in assessing the performance of the CMS computing jobs. The screenshot below shows the result of my work on the performance service frontend this summer that is available on the CMSWeb Testbed.
Technologies
- Big-data storage backend: Apache Hadoop
- Aggregation pipeline: Apache Spark, MongoDB, Python
- REST web server: WMArchive, Python
- Frontend: JavaScript with Backbone.js, HTML, CSS, Sass
- Visualization: D3.js
Documentation
Preparation:
Usage and Implementation:
Aggregation and Data:
Outlook:
Progress Reports
These reports document my weekly progress on the project. Please also refer to them for detailed documentation on the project: